ENGINEERING SOLUTIONS
How to Make Distributed Workflows Retry-Safe

Nick Lotz
Content Engineer
Last updated: March 6, 2026
March 6, 2026
12 min read








Mar 17, 2026

Mar 24, 2026
Mar 17, 2026
Join thousands of developers building the future with Orkes.
Consider a customer checking out in your app. A worker calls the processor, waits a few seconds, hits a timeout, and retries. The first call actually succeeded, but your system did not know it yet. The retry succeeds too. One order, two charges. Nobody wrote "charge twice" in the code, but that is still the outcome.
This is exactly why idempotency matters. Idempotency means that if the same logical operation is attempted multiple times, the external outcome is the same as if it ran once. Retries are necessary in distributed systems, but retries without idempotency can produce duplicate side effects.
Financial services has seen how expensive control failures can be. In 2020, Citibank accidentally sent about $900 million to Revlon lenders during a payment operation. That incident had broader operational causes than retry logic alone, but it still illustrates that in distributed systems, workflows can be triggered or replayed more than once for reasons you cannot always predict.
Earlier systems usually kept business logic in one application and one relational database. Consistency was easier because one transaction boundary could protect the operation end to end. If something failed, the transaction rolled back.
As architecture shifted to services, each business action started crossing boundaries through APIs and queues. Technologies like REST services and Kafka improved scaling and team ownership, but they also introduced new failure points between steps.
To avoid dropping work, platforms standardized retries and at-least-once delivery. That improved reliability, but it moved correctness into application design. Instead of relying on a single database transaction for safety, developers now must design workers to handle repeated messages safely and work correctly if tasks are replayed.
So we solved one problem very well, resilience to transient failure. The remaining challenge is guaranteeing one business outcome when the system retries after uncertain results.
For example, imagine an order-confirmation workflow that sends an email after inventory is reserved. The send call succeeds, but the worker times out before recording completion. The task is retried, and the customer receives the same confirmation twice. The system was resilient, but the business outcome was wrong. Retry safety is about making that second attempt return the same result instead of repeating the side effect.
As systems grow, business processes stop living in one place. A single user action might touch a payment API, an internal service, a queue, and a notification provider. Each step can succeed or fail independently. Teams usually patch this with local retry logic, but absent proper idempotency, that often creates inconsistent behavior across services.
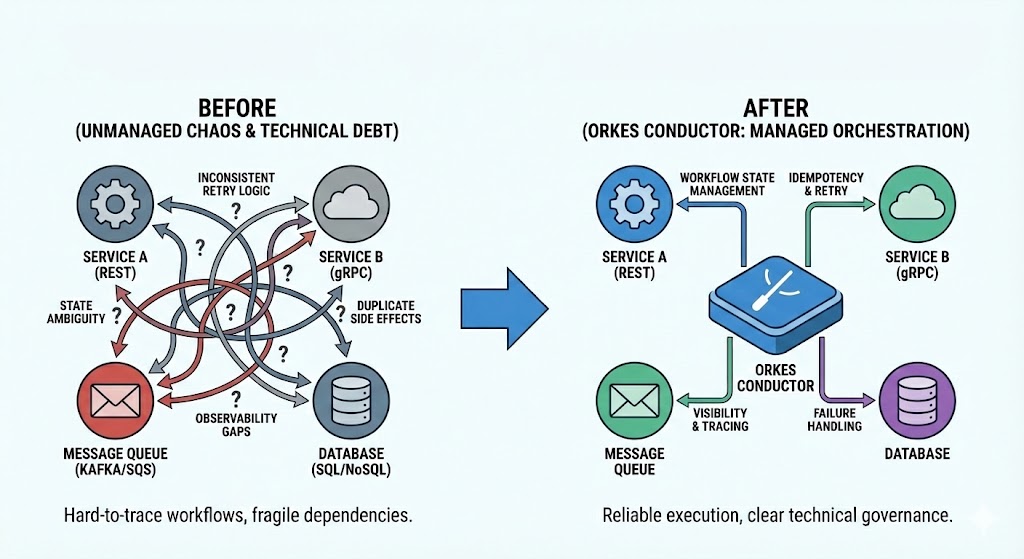
You can turn this maze into a more managed process by using software orchestration. In simple terms, orchestration means defining a business flow as a sequence of coordinated steps and letting one system manage execution state, retries, timeouts, dependencies, and failure handling. Instead of every service deciding process behavior on its own, orchestration provides one control plane for the whole workflow.
Tools like Conductors were created to accomplish this. Netflix Conductor was built to be a workflow orchestration for distributed, long-running work. Orkes Conductor provides that engine as a production-ready platform with visibility and operational controls. It gives you a durable workflow state, consistent retry behavior, and clear task lifecycle management. That directly reduces the pain points we started with: you stop relying on scattered retry code, you gain traceability across steps, and when paired with idempotent workers, retries remain reliable without creating duplicate side effects.
So far, we’ve talked about the problem in the abstract: retries are necessary, but retries alone do not protect business outcomes. Now we’ll make that concrete by building a complete, runnable example that combines orchestration and idempotency in one flow.
The application we’re simulating is a small checkout payment flow. A “start workflow” call represents the checkout app creating a payment request. Conductor schedules a charge_card task, and a Python worker processes it with idempotency protection. The worker calls a simulated payment side effect backed by a local durable ledger, then reports completion to Conductor. You will run all of this in a local VM, replay the same order, and verify that retries still progress the workflow while producing only one effective charge.
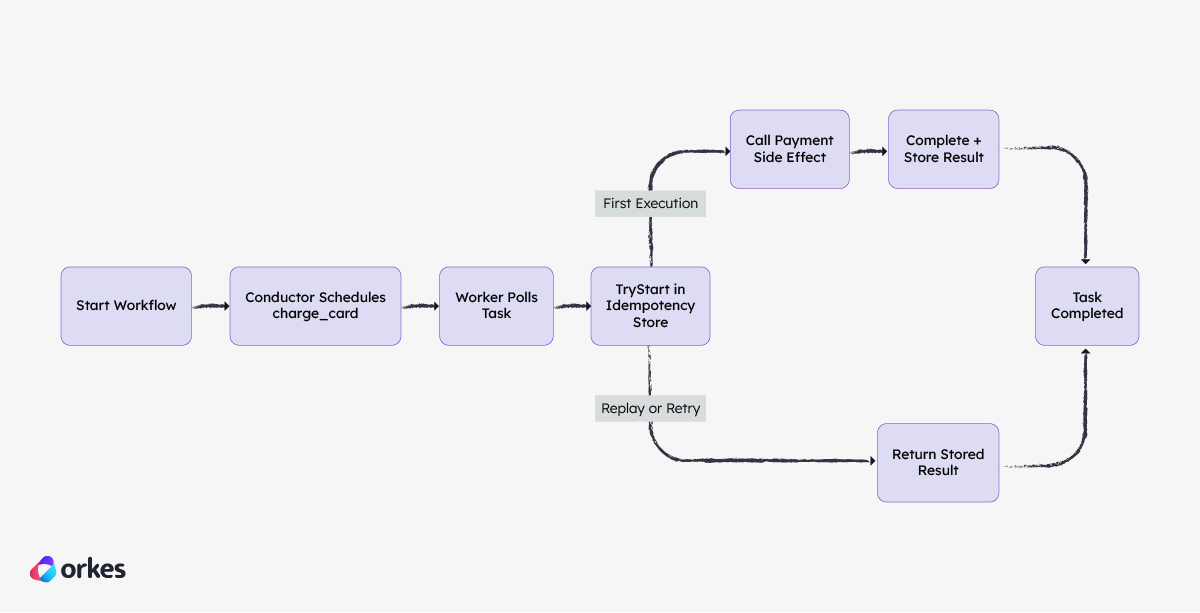
The key idea in this flow is that Orkes Conductor continues to do what it should do: deliver tasks reliably and retry when needed. Idempotency is enforced at the worker boundary. On each task, the worker first calls TryStart against the idempotency store. If this is the first valid execution, it performs the side effect and stores the durable result. If Conductor replays the same business operation later, the worker sees the existing record and returns the stored result instead of firing the side effect again. That is how you get retry resilience and one business outcome at the same time.
All code for this demo can be found in this GitHub repo, which we will now proceed to walk through together:
https://github.com/orkes-io/conductor-idempotency-demo
Install Multipass if needed. Multipass is a program from Canonical that lets you spawn on-demand Ubuntu VMs on your local machine. We’ll use it to keep this walkthrough sandboxed.
On macOS:
brew install --cask multipass
On Ubuntu/Linux:
sudo snap install multipass
On Windows (PowerShell):
winget install Canonical.Multipass
Sanity check:
multipass version
Then clone the demo repository and enter it:
git clone https://github.com/orkes-io/conductor-idempotency-demo.git
cd conductor-idempotency-demo
From repository root:
make vm-up
make vm-provision
make conductor-up
This creates a repeatable local runtime:
idempotency-retry-demoidempotency-retry-demo-conductor/home/ubuntu/.venvs/idempotency-retry-demoAll three commands are idempotent. If a run is interrupted, rerun the same commands.
Set the API endpoint in your shell:
VM_IP=$(multipass info idempotency-retry-demo | awk '/IPv4/{print $2}')
export CONDUCTOR_SERVER_URL="http://${VM_IP}:8080/api"
echo "${CONDUCTOR_SERVER_URL}"
Check the API responds:
curl -sS "${CONDUCTOR_SERVER_URL}/metadata/taskdefs" | head -c 200 && echo
You should get JSON back.
cd code
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Now your shell can run worker and verification scripts directly.
./register_conductor_assets.sh
First run usually says Created .... Later runs may say Updated ... or already exists .... All are acceptable.
Start one workflow execution:
export WF_ID_1=$(ORDER_ID=9243 ./start_workflow.sh)
echo "${WF_ID_1}"
Run the worker:
WORKER_INSTANCE_ID=worker-local-1 python3 run_conductor_worker.py --max-empty-polls 10
Verify workflow status:
curl -sS "${CONDUCTOR_SERVER_URL}/workflow/${WF_ID_1}" | jq '.status'
Expected output:
"COMPLETED"
Start a second workflow with the same business identity:
export WF_ID_2=$(ORDER_ID=9243 ./start_workflow.sh)
echo "${WF_ID_2}"
WORKER_INSTANCE_ID=worker-local-1 python3 run_conductor_worker.py --max-empty-polls 10
Compare charge_id across both workflow runs:
python3 - <<'PY'
import os
import requests
base = os.environ["CONDUCTOR_SERVER_URL"]
wf1 = os.environ["WF_ID_1"]
wf2 = os.environ["WF_ID_2"]
def get_charge_id(wf_id: str) -> str:
data = requests.get(f"{base}/workflow/{wf_id}", timeout=30).json()
tasks = data.get("tasks", [])
charge = [t for t in tasks if t.get("taskType") == "charge_card"]
if not charge:
return "missing"
return charge[-1].get("outputData", {}).get("charge_id", "missing")
charge1 = get_charge_id(wf1)
charge2 = get_charge_id(wf2)
print("wf1 charge_id:", charge1)
print("wf2 charge_id:", charge2)
print("same charge id:", charge1 == charge2)
PY
same charge id: True is the core proof.
Isolate the critical failure window (side effect succeeded, completion not yet written):
python3 run_demo.py --reset-db --scenario crash-retry
Expected output includes a simulated crash and replay result with side_effect_executed: false.
python3 run_demo.py --reset-db --scenario owner-conflict
Expected output includes:
owner conflict scenario: in progress
That confirms duplicate worker paths are controlled and retryable.
You proved the model locally. Now run the same flow in Orkes Developer Edition to confirm the behavior holds in a managed environment.
Start in the demo directory and set your endpoint and API credentials:
cd blogs/idempotency-and-retry-safety-in-distributed-workflows/code
export CONDUCTOR_SERVER_URL="https://developer.orkescloud.com/api"
export CONDUCTOR_AUTH_KEY="<your-key-id>"
export CONDUCTOR_AUTH_SECRET="<your-key-secret>"
Next, exchange key/secret for a short-lived token. The scripts in this demo use that token automatically.
export CONDUCTOR_AUTH_TOKEN="$(
curl -sS -X POST \
-H "Content-Type: application/json" \
--data "{\"keyId\":\"${CONDUCTOR_AUTH_KEY}\",\"keySecret\":\"${CONDUCTOR_AUTH_SECRET}\"}" \
"${CONDUCTOR_SERVER_URL}/token" \
| python3 -c 'import json,sys; print(json.load(sys.stdin)["token"])'
)"
Register task and workflow metadata. This command is idempotent, so reruns are safe.
./register_conductor_assets.sh
Run the first execution for ORDER_ID=9243, then run the worker to process it.
export WF_ID_CLOUD_1=$(ORDER_ID=9243 ./start_workflow.sh)
echo "${WF_ID_CLOUD_1}"
WORKER_INSTANCE_ID=worker-cloud-1 \
python3 run_conductor_worker.py \
--db-path /tmp/idempotency-retry-demo-cloud.sqlite \
--max-empty-polls 20
Now replay the same business operation (ORDER_ID=9243) and process it again with the same worker state.
export WF_ID_CLOUD_2=$(ORDER_ID=9243 ./start_workflow.sh)
echo "${WF_ID_CLOUD_2}"
WORKER_INSTANCE_ID=worker-cloud-1 \
python3 run_conductor_worker.py \
--db-path /tmp/idempotency-retry-demo-cloud.sqlite \
--max-empty-polls 20
If any command returns 401, refresh CONDUCTOR_AUTH_TOKEN and rerun that command.
Finally, compare both workflow runs. You should see both complete, and both reference the same charge_id.
python3 - <<'PY'
import os
import requests
base = os.environ["CONDUCTOR_SERVER_URL"]
wf1 = os.environ["WF_ID_CLOUD_1"]
wf2 = os.environ["WF_ID_CLOUD_2"]
token = os.getenv("CONDUCTOR_AUTH_TOKEN", "")
headers = {"X-Authorization": token} if token else {}
def read_workflow(workflow_id: str) -> dict:
return requests.get(f"{base}/workflow/{workflow_id}", headers=headers, timeout=30).json()
def read_charge_id(workflow: dict) -> str:
tasks = workflow.get("tasks", [])
charge_tasks = [t for t in tasks if t.get("taskType") == "charge_card"]
if not charge_tasks:
return "missing"
return charge_tasks[-1].get("outputData", {}).get("charge_id", "missing")
wf1_data = read_workflow(wf1)
wf2_data = read_workflow(wf2)
charge1 = read_charge_id(wf1_data)
charge2 = read_charge_id(wf2_data)
print("wf1 status:", wf1_data.get("status"))
print("wf2 status:", wf2_data.get("status"))
print("wf1 charge_id:", charge1)
print("wf2 charge_id:", charge2)
print("same charge id:", charge1 == charge2)
PY
Reliability is not just retrying faster, but rather is making each business operation replay-safe by design. We use orchestration to manage state across failures, and idempotency to make repeated attempts converge on one correct outcome instead of duplicate side effects. And, if you have not run this in Orkes Cloud yet, this is a good point to sign up and validate the same behavior in a managed environment with your own workflows.